![]()
2024 The Most Effective MCIA-Level-1 with 246 Questions Answers
Try Free and Start Using Realistic Verified MCIA-Level-1 Dumps Instantly.
The MCIA-Level-1 certification exam focuses on assessing an individual's knowledge of MuleSoft's Anypoint Platform and its various components. MCIA-Level-1 exam is designed to test the individual's ability to design, develop, and implement MuleSoft solutions that can integrate with various systems and applications. It also assesses the individual's understanding of best practices and industry standards related to integration architecture.
To take the MCIA-Level-1 exam, candidates must have a solid understanding of integration concepts and have experience using MuleSoft's Anypoint Platform. They should also have experience designing and implementing complex integration solutions in a variety of industries and have a strong understanding of integration patterns and best practices.
NEW QUESTION # 21
An organization has various integrations implemented as Mule applications. Some of these Mule applications are deployed to customer-hosted Mule runtimes (on-premises) while others execute in the MuleSoft-hosted runtime plane (CloudHub). To perform the integration functionality, these Mule applications connect to various backend systems, with multiple applications typically needing to access the same backend systems.
How can the organization most effectively avoid creating duplicates in each Mule application of the credentials required to access the backend systems?
- A. Segregate the credentials for each backend system into environment-specific properties files Package these properties files in each Mule application, from where they are loaded at startup
- B. Store the credentials in properties files in a shared folder within the organization's data center Have the Mule applications load properties files from this shared location at startup
- C. Configure or create a credentials service that returns the credentials for each backend system, and that is accessible from customer-hosted and MuleSoft-hosted Mule runtimes Have the Mule applications load the properties at startup by invoking that credentials service
- D. Create a Mule domain project that maintains the credentials as Mule domain-shared resources Deploy the Mule applications to the Mule domain, so the credentials are available to the Mule applications
Answer: C
NEW QUESTION # 22
Additional nodes are being added to an existing customer-hosted Mule runtime cluster to improve performance. Mule applications deployed to this cluster are invoked by API clients through a load balancer.
What is also required to carry out this change?
- A. New firewall rules must be configured to accommodate communication between API clients and the new nodes
- B. API implementations using an object store must be adjusted to recognize the new nodes and persist to them
- C. A new load balancer must be provisioned to allow traffic to the new nodes in a round-robin fashion
- D. External monitoring tools or log aggregators must be configured to recognize the new nodes
Answer: D
Explanation:
* Clustering is a group of servers or mule runtime which acts as a single unit.
* Mulesoft Enterprise Edition supports scalable clustering to provide high availability for the Mulesoft application.
* In simple terms, virtual servers composed of multiple nodes and they communicate and share information through a distributed shared memory grid.
* By default, Mulesoft ensures the High availability of applications if clustering implemented.
* Let's consider the scenario one of the nodes in cluster crashed or goes down and under maintenance. In such cases, Mulesoft will ensure that requests are processed by other nodes in the cluster. Mulesoft clustering also ensures that the request is load balanced between all the nodes in a cluster.
* Clustering is only supported by on-premise Mule runtime and it is not supported in Cloudhub.
Correct answer is External monitoring tools or log aggregators must be configured to recognize the new nodes
* Rest of the options are automatically taken care of when a new node is added in cluster.
Reference: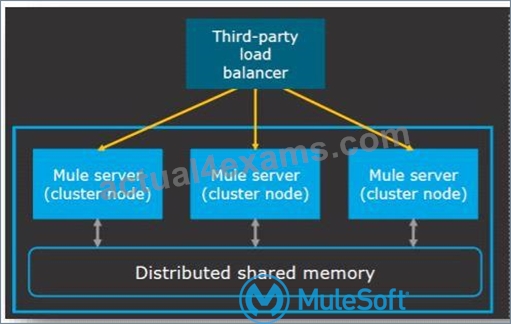
NEW QUESTION # 23
An API implementation is being developed to expose data from a production database via HTTP requests. The API implementation executes a database SELECT statement that is dynamically created based upon data received from each incoming HTTP request. The developers are planning to use various types of testing to make sure the Mule application works as expected, can handle specific workloads, and behaves correctly from an API consumer perspective. What type of testing would typically mock the results from each SELECT statement rather than actually execute it in the production database?
- A. Integration testing
- B. Performance testing
- C. Unit testing (white box)
- D. Functional testing (black box)
Answer: C
Explanation:
In Unit testing instead of using actual backends, stubs are used for the backend services. This ensures that developers are not blocked and have no dependency on other systems.
NEW QUESTION # 24
Refer to the exhibit.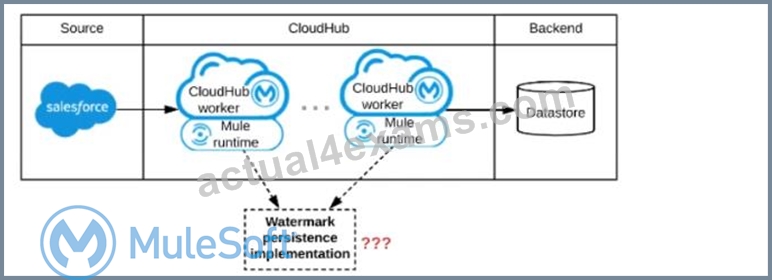
A Mule application is being designed to be deployed to several CIoudHub workers. The Mule application's integration logic is to replicate changed Accounts from Satesforce to a backend system every 5 minutes.
A watermark will be used to only retrieve those Satesforce Accounts that have been modified since the last time the integration logic ran.
What is the most appropriate way to implement persistence for the watermark in order to support the required data replication integration logic?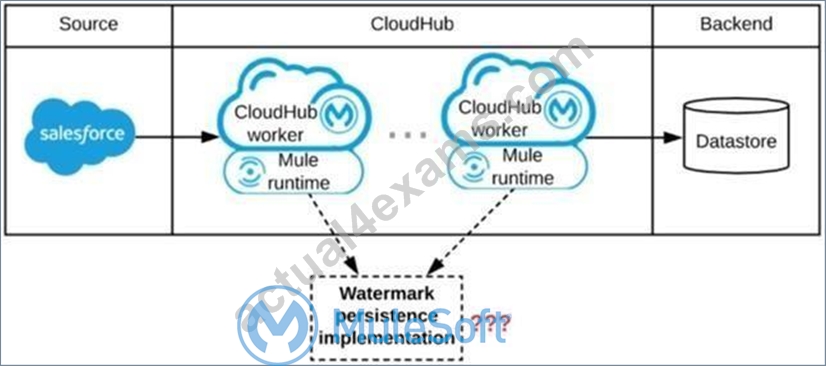
- A. Persistent Cache Scope
- B. Persistent Anypoint MQ Queue
- C. Persistent VM Queue
- D. Persistent Object Store
Answer: D
Explanation:
* An object store is a facility for storing objects in or across Mule applications. Mule uses object stores to persist data for eventual retrieval.
* Mule provides two types of object stores:
1) In-memory store - stores objects in local Mule runtime memory. Objects are lost on shutdown of the Mule runtime.
2) Persistent store - Mule persists data when an object store is explicitly configured to be persistent.
In a standalone Mule runtime, Mule creates a default persistent store in the file system. If you do not specify an object store, the default persistent object store is used.
MuleSoft Reference: https://docs.mulesoft.com/mule-runtime/3.9/mule-object-stores
NEW QUESTION # 25
What metrics about API invocations are available for visualization in custom charts using Anypoint Analytics?
- A. Request size, number of requests, JDBC Select operation result set size
- B. Request size, request HTTP verbs, response time
- C. Request size, number of requests, JDBC Select operation response time
- D. Request size, number of requests, response size, response time
Answer: D
Explanation:
Correct answer is Request size, number of requests, response size, response time Analytics API Analytics can provide insight into how your APIs are being used and how they are performing. From API Manager, you can access the Analytics dashboard, create a custom dashboard, create and manage charts, and create reports. From API Manager, you can get following types of analytics: - API viewing analytics - API events analytics - Charted metrics in API Manager It can be accessed using: http://anypoint.mulesoft.com/analytics API Analytics provides a summary in chart form of requests, top apps, and latency for a particular duration.
The custom dashboard in Anypoint Analytics contains a set of charts for a single API or for all APIs Each chart displays various API characteristics
- Requests size: Line chart representing size of requests in KBs
- Requests : Line chart representing number of requests over a period
- Response size : Line chart representing size of response in KBs
- Response time :Line chart representing response time in ms
* To check this, You can go to API Manager > Analytics > Custom Dashboard > Edit Dashboard > Create Chart > Metric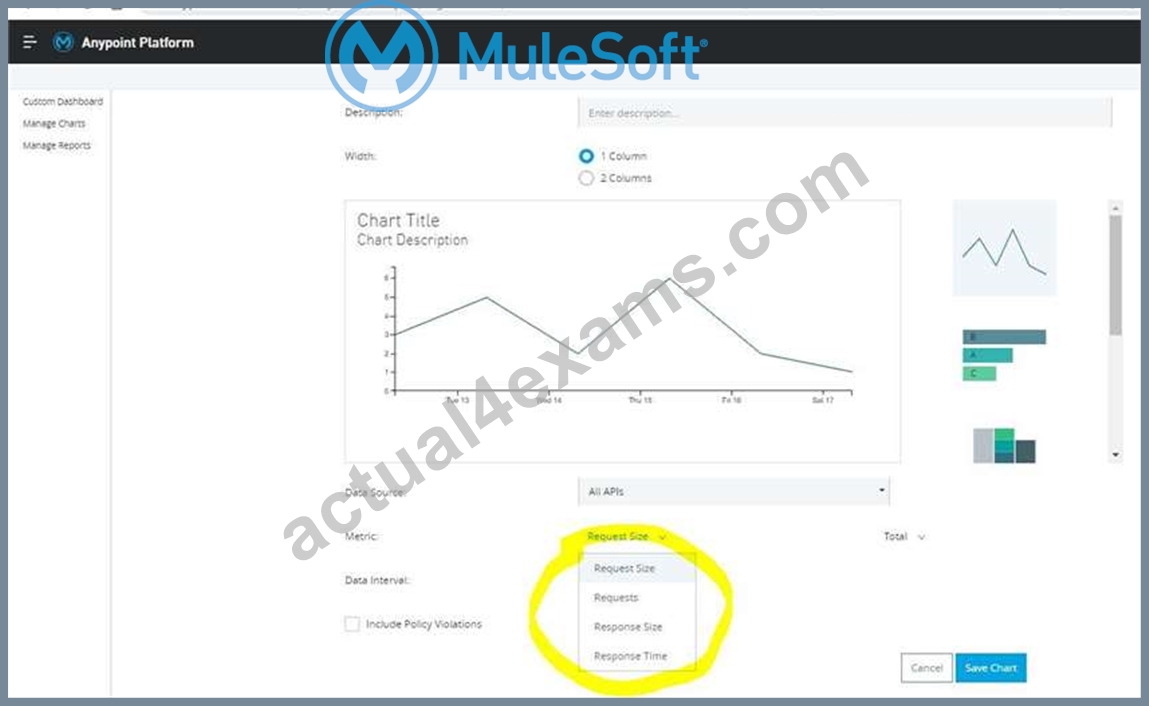
Reference:
Additional Information:
The default dashboard contains a set of charts
- Requests by date: Line chart representing number of requests
- Requests by location: Map chart showing the number of requests for each country of origin
- Requests by application: Bar chart showing the number of requests from each of the top five registered applications
- Requests by platform: Ring chart showing the number of requests broken down by platform
NEW QUESTION # 26
An API client is implemented as a Mule application that includes an HTTP Request operation using a default configuration. The HTTP Request operation invokes an external API that follows standard HTTP status code conventions, which causes the HTTP Request operation to return a 4xx status code.
What is a possible cause of this status code response?
- A. The external API reported that the API implementation has moved to a different external endpoint
- B. The external API reported an error with the HTTP request that was received from the outbound HTTP Request operation of the Mule application
- C. The HTTP response cannot be interpreted by the HTTP Request operation of the Mule application after it was received from the external API
- D. An error occurred inside the external API implementation when processing the HTTP request that was received from the outbound HTTP Request operation of the Mule application
Answer: C
Explanation:
Explanation/Reference: https://docs.mulesoft.com/connectors/http/http-request-ref
NEW QUESTION # 27
What Is a recommended practice when designing an integration Mule 4 application that reads a large XML payload as a stream?
- A. The payload should be dealt with as an XML stream, without converting it to a single Java object (POJO)
- B. The payload must be cached using a Cache scope If It Is to be sent to multiple backend systems
- C. The payload size should NOT exceed the maximum available heap memory of the Mute runtime on which the Mule application executes
- D. The payload should be dealt with as a repeatable XML stream, which must only be traversed (iterated-over) once and CANNOT be accessed randomly from DataWeave expressions and scripts
Answer: C
Explanation:
If the size of the stream exceeds the maximum, a STREAM_MAXIMUM_SIZE_EXCEEDED error is raised.
NEW QUESTION # 28
Refer to the exhibit.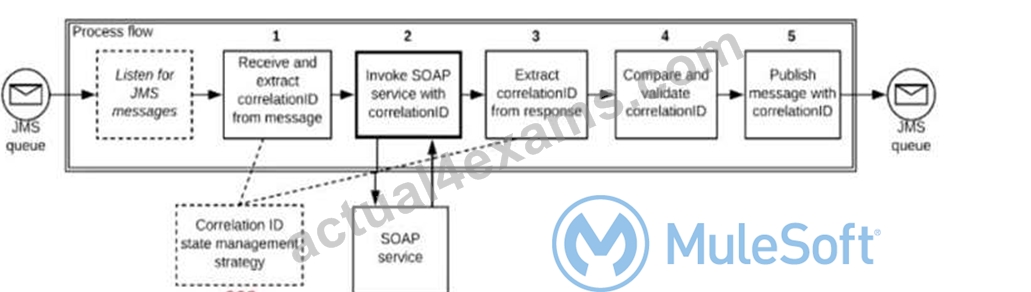
A Mule application is deployed to a multi-node Mule runtime cluster. The Mule application uses the competing consumer pattern among its cluster replicas to receive JMS messages from a JMS queue. To process each received JMS message, the following steps are performed in a flow:
Step l: The JMS Correlation ID header is read from the received JMS message.
Step 2: The Mule application invokes an idempotent SOAP webservice over HTTPS, passing the JMS Correlation ID as one parameter in the SOAP request.
Step 3: The response from the SOAP webservice also returns the same JMS Correlation ID.
Step 4: The JMS Correlation ID received from the SOAP webservice is validated to be identical to the JMS Correlation ID received in Step 1.
Step 5: The Mule application creates a response JMS message, setting the JMS Correlation ID message header to the validated JMS Correlation ID and publishes that message to a response JMS queue.
Where should the Mule application store the JMS Correlation ID values received in Step 1 and Step 3 so that the validation in Step 4 can be performed, while also making the overall Mule application highly available, fault-tolerant, performant, and maintainable?
- A. Both Correlation ID values should be stored as Mule event vanabtes/attnbutes
- B. The Correlation ID value in Step 1 should be stored in a persistent object store The Correlation ID value in step 3 should be stored as a Mule event vanable/attnbute
- C. Both Correlation ID values should be stored In a non-persistent object store
- D. Both Correlation ID values should be stored in a persistent object store
Answer: B
NEW QUESTION # 29
Refer to the exhibit.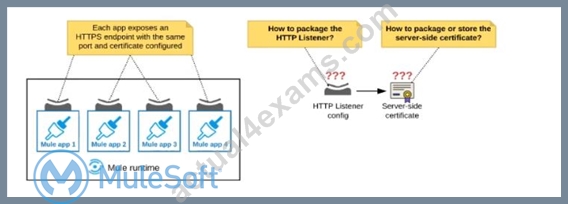
An organization deploys multiple Mule applications to the same customer -hosted Mule runtime. Many of these Mule applications must expose an HTTPS endpoint on the same port using a server-side certificate that rotates often.
What is the most effective way to package the HTTP Listener and package or store the server-side certificate when deploying these Mule applications, so the disruption caused by certificate rotation is minimized?
- A. Package an HTTPS Listener configuration In all Mule APPLICATIONS that need to expose an HTTPS endpoint Package the server-side certificate in a NEW Mule DOMAIN project
- B. Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint Package the server-side certificate in ALL Mule APPLICATIONS that need to expose an HTTPS endpoint
- C. Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing It from all Mule applications that need to expose an HTTPS endpoint. Package the server-side certificate in the SAME Mule DOMAIN project Go to Set
- D. Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Store the server-side certificate in a shared filesystem location in the Mule runtime's classpath, OUTSIDE the Mule DOMAIN or any Mule APPLICATION
Answer: D
Explanation:
In this scenario, both A & C will work, but A is better as it does not require repackage to the domain project at all.
Correct answer is Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Store the server-side certificate in a shared filesystem location in the Mule runtime's classpath, OUTSIDE the Mule DOMAIN or any Mule APPLICATION.
What is Mule Domain Project?
* A Mule Domain Project is implemented to configure the resources that are shared among different projects. These resources can be used by all the projects associated with this domain. Mule applications can be associated with only one domain, but a domain can be associated with multiple projects. Shared resources allow multiple development teams to work in parallel using the same set of reusable connectors. Defining these connectors as shared resources at the domain level allows the team to: - Expose multiple services within the domain through the same port. - Share the connection to persistent storage. - Share services between apps through a well-defined interface. - Ensure consistency between apps upon any changes because the configuration is only set in one place.
* Use domains Project to share the same host and port among multiple projects. You can declare the http connector within a domain project and associate the domain project with other projects. Doing this also allows to control thread settings, keystore configurations, time outs for all the requests made within multiple applications. You may think that one can also achieve this by duplicating the http connector configuration across all the applications. But, doing this may pose a nightmare if you have to make a change and redeploy all the applications.
* If you use connector configuration in the domain and let all the applications use the new domain instead of a default domain, you will maintain only one copy of the http connector configuration. Any changes will require only the domain to the redeployed instead of all the applications.
You can start using domains in only three steps:
1) Create a Mule Domain project
2) Create the global connector configurations which needs to be shared across the applications inside the Mule Domain project
3) Modify the value of domain in mule-deploy.properties file of the applications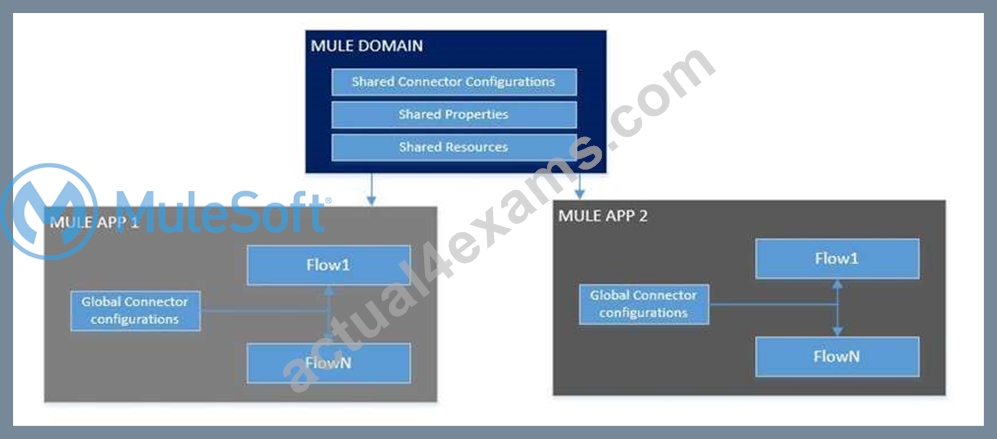
Use a certificate defined in already deployed Mule domain Configure the certificate in the domain so that the API proxy HTTPS Listener references it, and then deploy the secure API proxy to the target Runtime Fabric, or on-premises target. (CloudHub is not supported with this approach because it does not support Mule domains.)
NEW QUESTION # 30
An organization is building a test suite for their applications using m-unit. The integration architect has recommended using test recorder in studio to record the processing flows and then configure unit tests based on the capture events What are the two considerations that must be kept in mind while using test recorder (Choose two answers)
- A. Tests for flows cannot be created with Mule errors raised inside
the flow or already existing in the incoming event - B. The recorder support loops where the structure of the data been tested changes inside the iteration
- C. Recorder supports smoking a message before or inside a ForEach processor
- D. A recorded flow execution ends successfully but the result does
not reach its destination because the application is killed - E. Mocking values resulting from parallel processes are possible and will not affect the execution of the processes that follow in the test
Answer: A,D
NEW QUESTION # 31
Refer to the exhibit.
A shopping cart checkout process consists of a web store backend sending a sequence of API invocations to an Experience API, which in turn invokes a Process API. All API invocations are over HTTPS POST. The Java web store backend executes in a Java EE application server, while all API implementations are Mule applications executing in a customer -hosted Mule runtime.
End-to-end correlation of all HTTP requests and responses belonging to each individual checkout Instance is required. This is to be done through a common correlation ID, so that all log entries written by the web store backend, Experience API implementation, and Process API implementation include the same correlation ID for all requests and responses belonging to the same checkout instance.
What is the most efficient way (using the least amount of custom coding or configuration) for the web store backend and the implementations of the Experience API and Process API to participate in end-to-end correlation of the API invocations for each checkout instance?
A)
The web store backend, being a Java EE application, automatically makes use of the thread-local correlation ID generated by the Java EE application server and automatically transmits that to the Experience API using HTTP-standard headers No special code or configuration is included in the web store backend, Experience API, and Process API implementations to generate and manage the correlation ID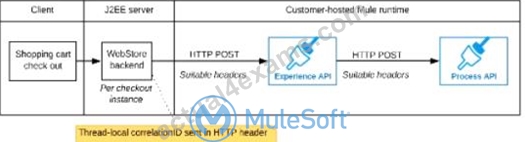
B)
The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATlON-lt HTTP request header In each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID
C)
The Experience API implementation generates a correlation ID for each incoming HTTP request and passes it to the web store backend in the HTTP response, which includes it in all subsequent API invocations to the Experience API.
The Experience API implementation must be coded to also propagate the correlation ID to the Process API in a suitable HTTP request header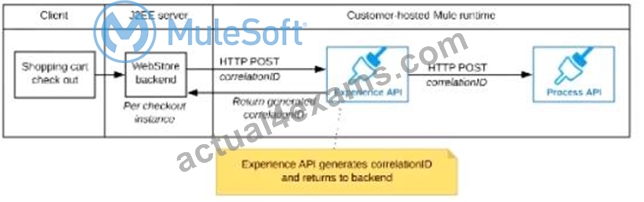
D)
The web store backend sends a correlation ID value in the HTTP request body In the way required by the Experience API The Experience API and Process API implementations must be coded to receive the custom correlation ID In the HTTP requests and propagate It in suitable HTTP request headers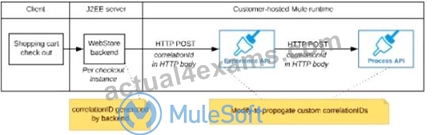
- A. Option C
- B. Option A
- C. Option D
- D. Option B
Answer: D
Explanation:
Correct answer is "The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATION-ID HTTP request header in each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID" Explanation: : By design, Correlation Ids cannot be changed within a flow in Mule 4 applications and can be set only at source. This ID is part of the Event Context and is generated as soon as the message is received by the application. When a HTTP Request is received, the request is inspected for "X-Correlation-Id" header. If "X-Correlation-Id" header is present, HTTP connector uses this as the Correlation Id. If "X-Correlation-Id" header is NOT present, a Correlation Id is randomly generated. For Incoming HTTP Requests: In order to set a custom Correlation Id, the client invoking the HTTP request must set "X-Correlation-Id" header. This will ensure that the Mule Flow uses this Correlation Id. For Outgoing HTTP Requests: You can also propagate the existing Correlation Id to downstream APIs. By default, all outgoing HTTP Requests send "X-Correlation-Id" header. However, you can choose to set a different value to "X-Correlation-Id" header or set "Send Correlation Id" to NEVER.
Mulesoft Reference: https://help.mulesoft.com/s/article/How-to-Set-Custom-Correlation-Id-for-Flows-with-HTTP-Endpoint-in-Mule-4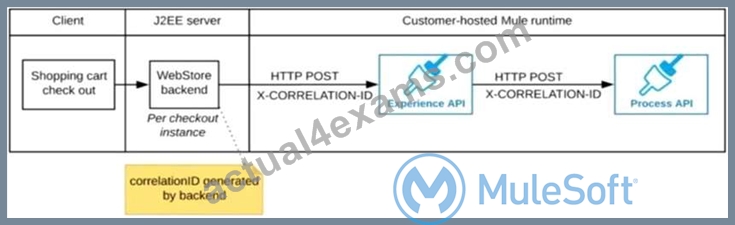
NEW QUESTION # 32
An organization has implemented the cluster with two customer hosted Mule runtimes is hosting an application.
This application has a flow with a JMS listener configured to consume messages from a queue destination. As an integration architect can you advise which JMS listener configuration must be used to receive messages in all the nodes of the cluster?
- A. Use the parameter primaryNodeOnly= "true" on the JMS listener
- B. Use the parameter primaryNodeOnly= "true" on the JMS listener with a nonshared subscription
- C. Use the parameter primaryNodeOnly= "false" on the JMS listener with a shared subscription
- D. Use the parameter primaryNodeOnly= "false" on the JMS listener
Answer: D
NEW QUESTION # 33
To implement predictive maintenance on its machinery equipment, ACME Tractors has installed thousands of IoT sensors that will send data for each machinery asset as sequences of JMS messages, in near real-time, to a JMS queue named SENSOR_DATA on a JMS server. The Mule application contains a JMS Listener operation configured to receive incoming messages from the JMS servers SENSOR_DATA JMS queue. The Mule application persists each received JMS message, then sends a transformed version of the corresponding Mule event to the machinery equipment back-end systems.
The Mule application will be deployed to a multi-node, customer-hosted Mule runtime cluster. Under normal conditions, each JMS message should be processed exactly once.
How should the JMS Listener be configured to maximize performance and concurrent message processing of the JMS queue?
- A. Set numberOfConsumers to a value greater than one
Set primaryNodeOnly = false - B. Set numberOfConsumers = 1
Set primaryNodeOnly = true - C. Set numberOfConsumers to a value greater than one
Set primaryNodeOnly = true - D. Set numberOfConsumers = 1
Set primaryNodeOnly = false
Answer: A
NEW QUESTION # 34
A retailer is designing a data exchange interface to be used by its suppliers. The interface must support secure communication over the public internet. The interface must also work with a wide variety of programming languages and IT systems used by suppliers.
What are suitable interface technologies for this data exchange that are secure, cross-platform, and internet friendly, assuming that Anypoint Connectors exist for these interface technologies?
- A. CSV over FTP YAML over TLS JSON over HTTPS
- B. XML over ActiveMQ XML over SFTP XML/REST over HTTPS
- C. EDJFACT XML over SFTP JSON/REST over HTTPS
- D. SOAP over HTTPS HOP over TLS gRPC over HTTPS
Answer: D
NEW QUESTION # 35
Refer to the exhibit.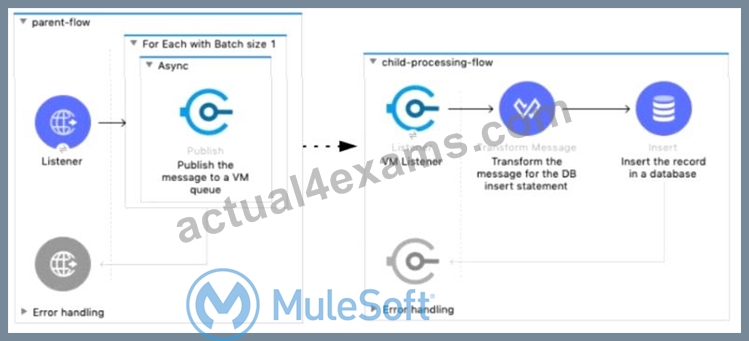
A Mule 4 application has a parent flow that breaks up a JSON array payload into 200 separate items, then sends each item one at a time inside an Async scope to a VM queue.
A second flow to process orders has a VM Listener on the same VM queue. The rest of this flow processes each received item by writing the item to a database.
This Mule application is deployed to four CloudHub workers with persistent queues enabled.
What message processing guarantees are provided by the VM queue and the CloudHub workers, and how are VM messages routed among the CloudHub workers for each invocation of the parent flow under normal operating conditions where all the CloudHub workers remain online?
- A. ALL Item VM messages are processed AT LEAST ONCE by the SAME CloudHub worker where the parent flow was invoked This one CloudHub worker processes ALL 200 item VM messages
- B. ALL item VM messages are processed AT MOST ONCE by ONE ARBITRARY CloudHub worker This one CloudHub worker processes ALL 200 item VM messages
- C. EACH item VM message is processed AT LEAST ONCE by ONE ARBITRARY CloudHub worker Each of the four CloudHub workers can be expected to process some item VM messages
- D. EACH item VM message is processed AT MOST ONCE by ONE CloudHub worker, with workers chosen in a deterministic round-robin fashion Each of the four CloudHub workers can be expected to process 1/4 of the Item VM messages (about 50 items)
Answer: C
NEW QUESTION # 36
An organization has deployed runtime fabric on an eight note cluster with performance profile. An API uses and non persistent object store for maintaining some of its state dat a. What will be the impact to the stale data if server crashes?
- A. State data is preserved
- B. State data is lost
- C. State data is rolled back to a previously saved version
- D. State data is preserved as long as more than one more is unaffected by the crash
Answer: D
NEW QUESTION # 37
Refer to the exhibit.
A shopping cart checkout process consists of a web store backend sending a sequence of API invocations to an Experience API, which in turn invokes a Process API. All API invocations are over HTTPS POST. The Java web store backend executes in a Java EE application server, while all API implementations are Mule applications executing in a customer -hosted Mule runtime.
End-to-end correlation of all HTTP requests and responses belonging to each individual checkout Instance is required. This is to be done through a common correlation ID, so that all log entries written by the web store backend, Experience API implementation, and Process API implementation include the same correlation ID for all requests and responses belonging to the same checkout instance.
What is the most efficient way (using the least amount of custom coding or configuration) for the web store backend and the implementations of the Experience API and Process API to participate in end-to-end correlation of the API invocations for each checkout instance?
A)
The web store backend, being a Java EE application, automatically makes use of the thread-local correlation ID generated by the Java EE application server and automatically transmits that to the Experience API using HTTP-standard headers No special code or configuration is included in the web store backend, Experience API, and Process API implementations to generate and manage the correlation ID
B)
The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATlON-lt HTTP request header In each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID
C)
The Experience API implementation generates a correlation ID for each incoming HTTP request and passes it to the web store backend in the HTTP response, which includes it in all subsequent API invocations to the Experience API.
The Experience API implementation must be coded to also propagate the correlation ID to the Process API in a suitable HTTP request header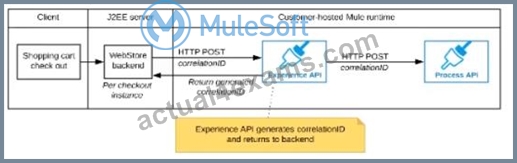
D)
The web store backend sends a correlation ID value in the HTTP request body In the way required by the Experience API The Experience API and Process API implementations must be coded to receive the custom correlation ID In the HTTP requests and propagate It in suitable HTTP request headers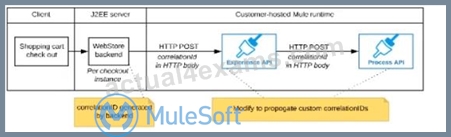
- A. Option C
- B. Option A
- C. Option D
- D. Option B
Answer: D
NEW QUESTION # 38
According to MuleSoft, a synchronous invocation of a RESTful API using HTTP to get an individual customer record from a single system is an example of which system integration interaction pattern?
- A. Batch
- B. Multicast
- C. One-way
- D. Request-Reply
Answer: D
NEW QUESTION # 39
An organization uses Mule runtimes which are managed by Anypoint Platform - Private Cloud Edition. What MuleSoft component is responsible for feeding analytics data to non-MuleSoft analytics platforms?
- A. Anypoint Exchange
- B. Anypoint Runtime Manager
- C. The Mule runtimes
- D. Anypoint API Manager
Answer: B
NEW QUESTION # 40
A Mule application contains a Batch Job with two Batch Steps (Batch_Step_l and Batch_Step_2). A payload with 1000 records is received by the Batch Job.
How many threads are used by the Batch Job to process records, and how does each Batch Step process records within the Batch Job?
- A. Each Batch Job uses SEVERAL THREADS for the Batch Steps Each Batch Step instance receives ONE record at a time as the payload, and RECORDS are processed IN PARALLEL within and between the two Batch Steps
- B. Each Batch Job uses a SINGLE THREAD for all Batch steps Each Batch step instance receives ONE record at a time as the payload, and RECORDS are processed IN ORDER, first through Batch_Step_l and then through Batch_Step_2
- C. Each Batch Job uses SEVERAL THREADS for the Batch Steps Each Batch Step instance receives ONE record at a time as the payload, and BATCH STEP INSTANCES execute IN PARALLEL to process records and Batch Steps in ANY order as fast as possible
- D. Each Batch Job uses a SINGLE THREAD to process a configured block size of record Each Batch Step instance receives A BLOCK OF records as the payload, and BLOCKS of records are processed IN ORDER
Answer: A
Explanation:
* Each Batch Job uses SEVERAL THREADS for the Batch Steps
* Each Batch Step instance receives ONE record at a time as the payload. It's not received in a block, as it does not wait for multiple records to be completed before moving to next batch step. (So Option D is out of choice)
* RECORDS are processed IN PARALLEL within and between the two Batch Steps.
* RECORDS are not processed in order. Let's say if second record completes batch_step_1 before record 1, then it moves to batch_step_2 before record 1. (So option C and D are out of choice)
* A batch job is the scope element in an application in which Mule processes a message payload as a batch of records. The term batch job is inclusive of all three phases of processing: Load and Dispatch, Process, and On Complete.
* A batch job instance is an occurrence in a Mule application whenever a Mule flow executes a batch job. Mule creates the batch job instance in the Load and Dispatch phase. Every batch job instance is identified internally using a unique String known as batch job instance id.
NEW QUESTION # 41
......
Becoming a MuleSoft Certified Integration Architect - Level 1 is a significant achievement for integration architects, as it demonstrates their expertise in using MuleSoft's Anypoint Platform to design and build complex integration solutions. MuleSoft Certified Integration Architect - Level 1 certification is recognized globally and can help professionals advance their careers and increase their earning potential. By passing the MCIA-Level-1 exam, candidates can join a community of certified MuleSoft professionals who are committed to delivering high-quality integration solutions.
Download Free Latest Exam MCIA-Level-1 Certified Sample Questions: https://www.actual4exams.com/MCIA-Level-1-valid-dump.html