![]()
New Actual4Exams Professional-Machine-Learning-Engineer Exam Questions| Real Professional-Machine-Learning-Engineer Dumps Updated on Nov 04, 2021
Professional-Machine-Learning-Engineer Braindumps – Professional-Machine-Learning-Engineer Questions to Get Better Grades
How to study the Professional Machine Learning Engineer - Google
A broad range of Google Professional-Machine-Learning-Engineer dumps for Google accredited Developer Certification have been recognized for certification issues. The reality that students need to prepare attentively does not make certificates easy. It also takes a long time to learn from Google accredited Developer. Every exam includes answers and questions that help students pass their final test. You will pass the test after you have taken and learned our modules. But it doesn’t end there; thanks to our full guides, you will still be good in your career. You will produce your goods in the future. To plan any material for you, we have an advanced method. In the development of and commodity, we have used the latest details.
We offer a terrific research study review and fantastic solutions for any type of expert who intends to take accreditation testing on the first initiative. By taking the training product developed by our professionals, you will have the opportunity to pass the exams in the very first effort. We provide a 100% guarantee of success and we are positive that you will certainly do well Actual4Exams is among the relied on, validated as well as valued sites giving its clients on the internet with extremely comprehensive and relevant online exam preparation items. Actual4Exams offers every little thing you need to pass the qualification test. If you are seeking a certification and are unsuccessful, currently is the moment for you to try what we provide. Google Professional-Machine-Learning-Engineer practice test and Google Professional-Machine-Learning-Engineer practice exam is easy to use, so that anyone can appreciate them.
NEW QUESTION 28
You have a functioning end-to-end ML pipeline that involves tuning the hyperparameters of your ML model using Al Platform, and then using the best-tuned parameters for training. Hypertuning is taking longer than expected and is delaying the downstream processes. You want to speed up the tuning job without significantly compromising its effectiveness. Which actions should you take?
Choose 2 answers
- A. Set the early stopping parameter to TRUE
- B. Decrease the maximum number of trials during subsequent training phases.
- C. Decrease the number of parallel trials
- D. Change the search algorithm from Bayesian search to random search.
- E. Decrease the range of floating-point values
Answer: D,E
NEW QUESTION 29
Your data science team needs to rapidly experiment with various features, model architectures, and hyperparameters. They need to track the accuracy metrics for various experiments and use an API to query the metrics over time. What should they use to track and report their experiments while minimizing manual effort?
- A. Use Kubeflow Pipelines to execute the experiments Export the metrics file, and query the results using the Kubeflow Pipelines API.
- B. Use Al Platform Notebooks to execute the experiments. Collect the results in a shared Google Sheets file, and query the results using the Google Sheets API
- C. Use Al Platform Training to execute the experiments Write the accuracy metrics to Cloud Monitoring, and query the results using the Monitoring API.
- D. Use Al Platform Training to execute the experiments Write the accuracy metrics to BigQuery, and query the results using the BigQueryAPI.
Answer: D
NEW QUESTION 30
The displayed graph is from a forecasting model for testing a time series.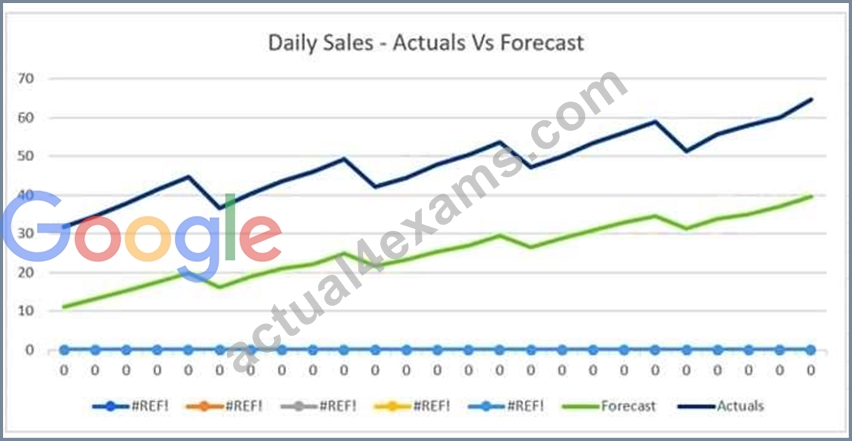
Considering the graph only, which conclusion should a Machine Learning Specialist make about the behavior of the model?
- A. The model predicts both the trend and the seasonality well
- B. The model does not predict the trend or the seasonality well.
- C. The model predicts the seasonality well, but not the trend.
- D. The model predicts the trend well, but not the seasonality.
Answer: B
NEW QUESTION 31
A company ingests machine learning (ML) data from web advertising clicks into an Amazon S3 data lake. Click data is added to an Amazon Kinesis data stream by using the Kinesis Producer Library (KPL). The data is loaded into the S3 data lake from the data stream by using an Amazon Kinesis Data Firehose delivery stream.
As the data volume increases, an ML specialist notices that the rate of data ingested into Amazon S3 is relatively constant. There also is an increasing backlog of data for Kinesis Data Streams and Kinesis Data Firehose to ingest.
Which next step is MOST likely to improve the data ingestion rate into Amazon S3?
- A. Increase the number of S3 prefixes for the delivery stream to write to.
- B. Increase the number of shards for the data stream.
- C. Add more consumers using the Kinesis Client Library (KCL).
- D. Decrease the retention period for the data stream.
Answer: B
Explanation:
Explanation/Reference:
NEW QUESTION 32
You recently designed and built a custom neural network that uses critical dependencies specific to your organization's framework. You need to train the model using a managed training service on Google Cloud. However, the ML framework and related dependencies are not supported by Al Platform Training. Also, both your model and your data are too large to fit in memory on a single machine. Your ML framework of choice uses the scheduler, workers, and servers distribution structure. What should you do?
- A. Build your custom container to run jobs on Al Platform Training
- B. Use a built-in model available on Al Platform Training
- C. Reconfigure your code to a ML framework with dependencies that are supported by Al Platform Training
- D. Build your custom containers to run distributed training jobs on Al Platform Training
Answer: D
NEW QUESTION 33
You built and manage a production system that is responsible for predicting sales numbers. Model accuracy is crucial, because the production model is required to keep up with market changes. Since being deployed to production, the model hasn't changed; however the accuracy of the model has steadily deteriorated. What issue is most likely causing the steady decline in model accuracy?
- A. Incorrect data split ratio during model training, evaluation, validation, and test
- B. Poor data quality
- C. Lack of model retraining
- D. Too few layers in the model for capturing information
Answer: A
NEW QUESTION 34
You need to train a computer vision model that predicts the type of government ID present in a given image using a GPU-powered virtual machine on Compute Engine. You use the following parameters:
* Optimizer: SGD
* Image shape = 224x224
* Batch size = 64
* Epochs = 10
* Verbose = 2
During training you encounter the following error: ResourceExhaustedError: out of Memory (oom) when allocating tensor. What should you do?
- A. Reduce the image shape
- B. Reduce the batch size
- C. Change the learning rate
- D. Change the optimizer
Answer: B
NEW QUESTION 35
You are training a Resnet model on Al Platform using TPUs to visually categorize types of defects in automobile engines. You capture the training profile using the Cloud TPU profiler plugin and observe that it is highly input-bound. You want to reduce the bottleneck and speed up your model training process. Which modifications should you make to the tf .data dataset?
Choose 2 answers
- A. Set the prefetch option equal to the training batch size
- B. Decrease the batch size argument in your transformation
- C. Increase the buffer size for the shuffle option.
- D. Use the interleave option for reading data
- E. Reduce the value of the repeat parameter
Answer: A,D
NEW QUESTION 36
You need to build classification workflows over several structured datasets currently stored in BigQuery. Because you will be performing the classification several times, you want to complete the following steps without writing code: exploratory data analysis, feature selection, model building, training, and hyperparameter tuning and serving. What should you do?
- A. Use Al Platform Notebooks to run the classification model with pandas library
- B. Run a BigQuery ML task to perform logistic regression for the classification
- C. Use Al Platform to run the classification model job configured for hyperparameter tuning
- D. Configure AutoML Tables to perform the classification task
Answer: A
NEW QUESTION 37
A Machine Learning Specialist is training a model to identify the make and model of vehicles in images. The Specialist wants to use transfer learning and an existing model trained on images of general objects. The Specialist collated a large custom dataset of pictures containing different vehicle makes and models.
What should the Specialist do to initialize the model to re-train it with the custom data?
- A. Initialize the model with pre-trained weights in all layers including the last fully connected layer.
- B. Initialize the model with random weights in all layers and replace the last fully connected layer.
- C. Initialize the model with random weights in all layers including the last fully connected layer.
- D. Initialize the model with pre-trained weights in all layers and replace the last fully connected layer.
Answer: D
NEW QUESTION 38
A Machine Learning Specialist has completed a proof of concept for a company using a small data sample, and now the Specialist is ready to implement an end-to-end solution in AWS using Amazon SageMaker. The historical training data is stored in Amazon RDS.
Which approach should the Specialist use for training a model using that data?
- A. Move the data to Amazon DynamoDB and set up a connection to DynamoDB within the notebook to pull data in.
- B. Write a direct connection to the SQL database within the notebook and pull data in
- C. Push the data from Microsoft SQL Server to Amazon S3 using an AWS Data Pipeline and provide the S3 location within the notebook.
- D. Move the data to Amazon ElastiCache using AWS DMS and set up a connection within the notebook to pull data in for fast access.
Answer: C
NEW QUESTION 39
Your organization wants to make its internal shuttle service route more efficient. The shuttles currently stop at all pick-up points across the city every 30 minutes between 7 am and 10 am. The development team has already built an application on Google Kubernetes Engine that requires users to confirm their presence and shuttle station one day in advance. What approach should you take?
- A. 1. Build a tree-based regression model that predicts how many passengers will be picked up at each shuttle station.
2. Dispatch an appropriately sized shuttle and provide the map with the required stops based on the prediction. - B. 1. Build a tree-based classification model that predicts whether the shuttle should pick up passengers at each shuttle station.
2. Dispatch an available shuttle and provide the map with the required stops based on the prediction - C. 1. Define the optimal route as the shortest route that passes by all shuttle stations with confirmed attendance at the given time under capacity constraints.
2 Dispatch an appropriately sized shuttle and indicate the required stops on the map - D. 1. Build a reinforcement learning model with tree-based classification models that predict the presence of passengers at shuttle stops as agents and a reward function around a distance-based metric
2. Dispatch an appropriately sized shuttle and provide the map with the required stops based on the simulated outcome.
Answer: A
NEW QUESTION 40
A trucking company is collecting live image data from its fleet of trucks across the globe. The data is growing rapidly and approximately 100 GB of new data is generated every day. The company wants to explore machine learning uses cases while ensuring the data is only accessible to specific IAM users.
Which storage option provides the most processing flexibility and will allow access control with IAM?
- A. Use a database, such as Amazon DynamoDB, to store the images, and set the IAM policies to restrict access to only the desired IAM users.
- B. Use an Amazon S3-backed data lake to store the raw images, and set up the permissions using bucket policies.
- C. Configure Amazon EFS with IAM policies to make the data available to Amazon EC2 instances owned by the IAM users.
- D. Setup up Amazon EMR with Hadoop Distributed File System (HDFS) to store the files, and restrict access to the EMR instances using IAM policies.
Answer: D
Explanation:
Explanation
NEW QUESTION 41
You have deployed multiple versions of an image classification model on Al Platform. You want to monitor the performance of the model versions overtime. How should you perform this comparison?
- A. Compare the mean average precision across the models using the Continuous Evaluation feature
- B. Compare the loss performance for each model on a held-out dataset.
- C. Compare the receiver operating characteristic (ROC) curve for each model using the What-lf Tool
- D. Compare the loss performance for each model on the validation data
Answer: D
NEW QUESTION 42
A company is using Amazon Textract to extract textual data from thousands of scanned text-heavy legal documents daily. The company uses this information to process loan applications automatically. Some of the documents fail business validation and are returned to human reviewers, who investigate the errors. This activity increases the time to process the loan applications.
What should the company do to reduce the processing time of loan applications?
- A. Use Amazon Rekognition's feature to detect text in an image to extract the data from scanned images. Use this information to process the loan applications.
- B. Use an Amazon Textract synchronous operation instead of an asynchronous operation.
- C. Configure Amazon Textract to route low-confidence predictions to Amazon Augmented AI (Amazon A2I).
Perform a manual review on those words before performing a business validation. - D. Configure Amazon Textract to route low-confidence predictions to Amazon SageMaker Ground Truth.
Perform a manual review on those words before performing a business validation.
Answer: C
NEW QUESTION 43
A data scientist has developed a machine learning translation model for English to Japanese by using Amazon SageMaker's built-in seq2seq algorithm with 500,000 aligned sentence pairs. While testing with sample sentences, the data scientist finds that the translation quality is reasonable for an example as short as five words. However, the quality becomes unacceptable if the sentence is 100 words long.
Which action will resolve the problem?
- A. Choose a different weight initialization type.
- B. Add more nodes to the recurrent neural network (RNN) than the largest sentence's word count.
- C. Adjust hyperparameters related to the attention mechanism.
- D. Change preprocessing to use n-grams.
Answer: B
NEW QUESTION 44
A Machine Learning Specialist is developing a daily ETL workflow containing multiple ETL jobs. The workflow consists of the following processes:
* Start the workflow as soon as data is uploaded to Amazon S3.
* When all the datasets are available in Amazon S3, start an ETL job to join the uploaded datasets with multiple terabyte-sized datasets already stored in Amazon S3.
* Store the results of joining datasets in Amazon S3.
* If one of the jobs fails, send a notification to the Administrator.
Which configuration will meet these requirements?
- A. Use AWS Lambda to trigger an AWS Step Functions workflow to wait for dataset uploads to complete in Amazon S3. Use AWS Glue to join the datasets. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
- B. Develop the ETL workflow using AWS Lambda to start an Amazon SageMaker notebook instance. Use a lifecycle configuration script to join the datasets and persist the results in Amazon S3. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
- C. Use AWS Lambda to chain other Lambda functions to read and join the datasets in Amazon S3 as soon as the data is uploaded to Amazon S3. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
- D. Develop the ETL workflow using AWS Batch to trigger the start of ETL jobs when data is uploaded to Amazon S3. Use AWS Glue to join the datasets in Amazon S3. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
Answer: A
Explanation:
Explanation/Reference: https://aws.amazon.com/step-functions/use-cases/
NEW QUESTION 45
......
Professional-Machine-Learning-Engineer Exam Dumps - Try Best Professional-Machine-Learning-Engineer Exam Questions: https://www.actual4exams.com/Professional-Machine-Learning-Engineer-valid-dump.html
Get New Professional-Machine-Learning-Engineer Certification – Valid Exam Dumps Questions: https://drive.google.com/open?id=1XS5R_jKWp1wLlu4Rto-0r1ie5Vfg1e52